

vSAN 7.0 U3 delivers improved performance with optimisations made to the data path when using RAID-5/6 erasure coding very similar to what was added to vSAN 7.0 U2 Performance enhancements , vSAN 7.0 U3 offers caching capability to the incoming writes who’s workloads are serialised and have sustained high outstanding IOPS, this caching capability for writes reduces significant amount of write amplification by enforcing full stripe writes always in the backend.This feature compliments the feature which was introduced with vSAN 7.0 U2 where the reads for large block sequential IOPS were cached.
To give a perspective of how standard writes are handled with RAID 6 , we will have a total of 6 operations (Read data, read parity-1, read parity-2, write data, write parity-1 and write parity-2) for every IO which is received from the guest, i.e 1000 IOPS from the guest will result in 6000 IOPS at the backend in vSAN, these IOPS will also have additional network overhead as these have to go to the respective hosts where the components for the VMs are placed resulting in low throughput and high latency.
Standard Write vs Strided Write
When cluster is upgraded to vSAN 7.0 U3, we will see a significant performance improvements for VMs which are always doing large sequential Write IOPS, where the incoming write IOPS are cached and it waits long enough to see a possibility for a full stripe write, i.e IOPS are not immediately committed to the backend rather cached in cache pages and when it receives enough data to perform a full stripe write, it simply clears the entire stripe row and commits a full-stripe write also called a “Strided Write“, which is completed in just two steps. This reduction in the write amplification also reduces the number IOPS which have to traverse between the host where the VM is running and where the components are placed. This overall achieves a very efficient, low latency and high throughput for the guest VM.
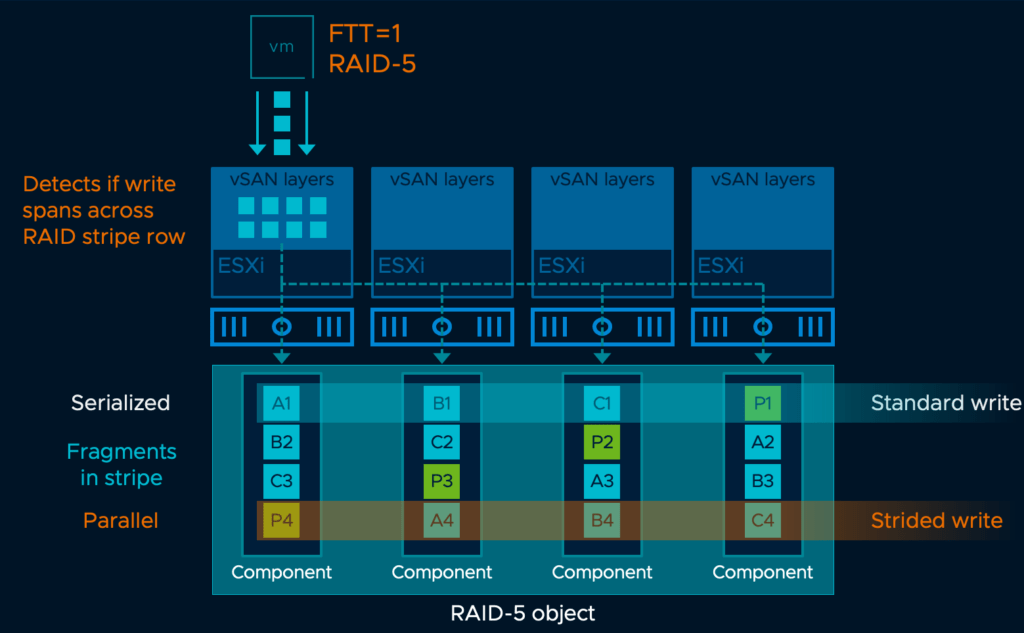
Above image is a similar example for a RAID-5 object, when the VM issues IOs to the backend usually it takes 4 operations with a standard write, however when cached and written as a strided write its achieved with just two steps. Once again we see that write amplification is reduced significantly by reducing number of operation needed to complete the IO at storage and network layer.
Strided write feature is always opportunistic and will generally work well with erasure coding R5/R6 for workloads with I/O sizes are sufficiently large enough to span across RAID row – 3MB for RAID-5, or 4MB for RAID-6. (e.g. 32 OIOs each with 128K I/O size) or write IO bursts – moderate OIO. (e.g. 8 OIO each with a 512KB I/O size).
Having explained the feature “standard write” vs “strided write“, vSAN does not always receive full stripe writes. If incoming writes are not sequential, does not have a lot if outstanding I/O, or does not exceed the size of the stripe row, the more-efficient strided write method will not be used. This is dynamically determined by vSAN and such cases it will have to fall back to standard write .
Strided writes are unable to be performed in a stretched cluster or 2-node where nested levels of resilience is used. In those topologies, the traditional method for writing data to the stripe is used instead.
For VMC Users
VMConAWS consumers will benefit from these enhancements around strided write performance starting from version M16 which is equivalent to vSAN 7.0 U3.

